General flowchart for primary data processing
Primary data as found in STOREFISH were processed into CSV files and treated as indicated in the figure below.
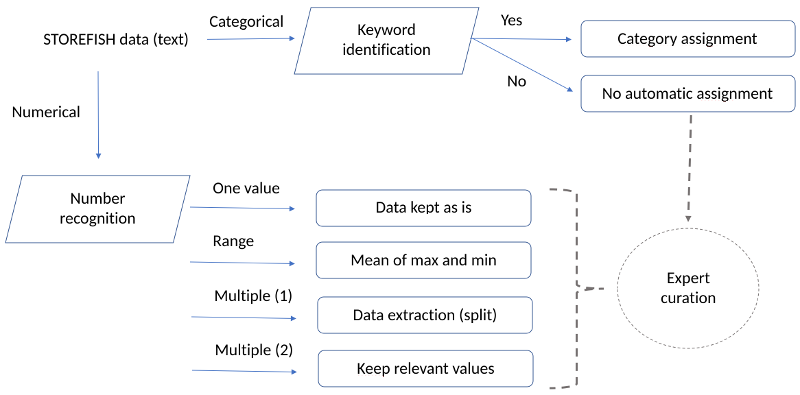
Briefly, each trait was modelled as being quantitative (numerical) or qualitative (categorical), and a dedicated data extraction routine was applied. When no unambiguous data could be assigned, expert curation by F. Téletchéa was performed.
Primary data extraction for numerical data
Python regular expression were used to identify numbers in raw number.One example of a regular expression is:
regex_number = r"\d+[\.]?\d*"
This expression will allow to search for a number(\d) present one or more times, with the possibility of finding decimals (plus sign), but not necessarily ([\.]?\d*). Many regular expressions were set up to retrieve unambiguously data from the raw primary data.
Primary data extraction for categorical data
All traits were defined as being present or absent, or pertaining to a short list of controlled vocabulary. A simple keyword search was performed in primary data allowed to unambiguously detect categories. When no category was detected but primary data was present, expert curation was involved.